

Recent social posts boasting “Grok remains parked at #1 as if it owned the place” capture a broader narrative we’ve seen all year. xAI Grok variants, especially Grok 4.1 Fast and Grok Code Fast 1, are being celebrated for dominating coding leaderboards and posting eye-watering token volumes on publicly used platforms. This claim is based on factual data (high usage, top positions on public leaderboards). Still, it’s also rooted in a noisy environment where leaderboard positioning and promotional access are just as important as raw capabilities.
In this article, you will learn about Grok coding leaderboard, and the evidence, context, caveats, and implications for engineers today are discussed when selecting a coding method.
What is Grok Coding?
Grok coding uses xAI Grok models for writing, analysing, fixing, or optimising code quickly. It has a low latency and high throughput, which makes it ideal for iterative coding and real-time development.
Grok Coding is unique
Grok is frequently highlighted for:
- High speed output
- Large context windows (useful for understanding multi-file projects)
- High performance on leaderboards for coding
- High throughput makes it ideal for rapid iteration
- Agentic abilities include reasoning about project structures or making step-bystep code improvements
What are the most common uses of Grok by developers?
- Write new scripts or modules, functions, or scripts
- Debugging and fixing errors in complex code
- Code optimization and refactoring
- Tests, documentation and comments
- Handling multi-file or long input contexts
- Assisting with real-time coding sessions that require fast turnaround
I can write an two line version or a glossary definition. Or, I can create a SEO optimized snippet.
What does the Grok Coding Leaderboard mean?
- Grok is the leader in coding.
- The token volume of Grok is rapidly increasing (stacked in its favor).
- Grok continues to lead the pack despite competitors’ updates.
- Grok is the best choice for developers who want to code quickly.
Each of these points corresponds to observable indicators: the public leaderboard positions, reported OpenRouter Token counts, and vendor documentation on Grok Code Fast 1. Each signal should be analyzed and interpreted in context. See below for sources and analysis.
Grok Code Fast 1 Continues Its Dominance Across Coding Leaderboards
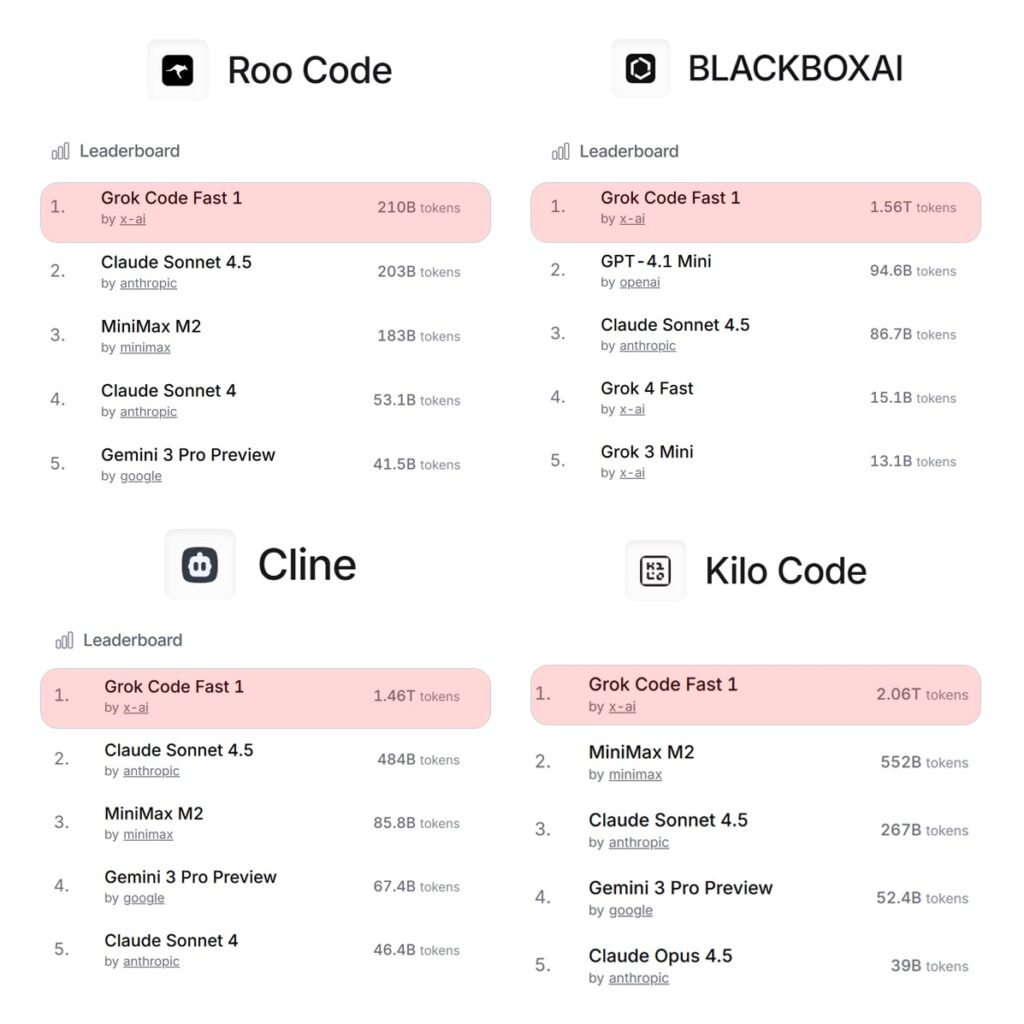
Overview
Grok Code Fast 1 has once again established itself at the top of several key coding benchmarks, confirming its leadership in the AI programming landscape. The consistent performance across different platforms demonstrates not only speed but also reliability and flexibility for developers in real-world situations.
Performance Highlights
- KiloCode: Grok Code Speed 1 is still in the number. Number one position due to its superior code generation precision and efficiency in problem-solving.
- RooCode: It shows unrivalled reasoning ability and code precision, edging out LLMs in complex tasks.
- BlackboxAI: Leads with higher completion rates and greater code correctness, making it the preferred option for workflows that require advanced.
- Cline: It remains the dominant choice for high-performance, stable outputs in agent-driven coding environments.
What This Means for Developers?
Grok’s streak of winning across all platforms indicates an essential shift in the code-assistant market. Developers can count Grok Code Fast 1 for: Grok Code Fast 1 for:
- Rapid prototyping
- Cleaner, better-maintained code
- Fewer errors and fewer rework cycles
- Performance is high across both large and small-scale programming tasks
Why Grok Code Fast 1 Stands Out?
Grok’s dominance is driven:
- Advanced thinking capabilities
- More efficient token throughput
- Improved support for multi-step as well as complicated programming tasks
- A consistently high leaderboard performance across a variety of independent evaluators
Grok coding leaderboard: The truth about public data
Leaderboard Appearance: Grok models are near the top of many public benchmarking leaderboards. This supports the claim that Grok appears at the top of several lists.
OpenRouter high Token Volumes: Reports, community posts, and other sources documented a dramatic spike in Grok 4.1 fast (reported figures around 253B to 334B daily tokens for 24 hours), which is why the “tokens keep stacking” statement was made. High token volume reflects real usage or free-access bursts.
Official Models pages and Specs: The Grok Code Fast 1, listed on OpenRouter, has large context windows as well as pricing/throughput features that make it appealing for high-volume tasks. These attributes help explain the rapid adoption of coding workflows.
Grok is a popular coding language.
Several practical, non-mystical reasons drive developer adoption and high numbers of throughput:
- Speed and Throughput: The “fast” variants are designed to emphasize throughput and latency, which are crucial for iterative prototyping and coding. Faster responses result in more tokens being consumed per hour.
- Large Context Window: Certain Grok variants allow for very long contexts. This allows the model to handle larger codebases within a single session.
- Promo / Free Access Windows: When models are made freely available (or heavily discounted), on routing platforms such as OpenRouter, or integrated into popular IDE plug-ins, usage increases — temporarily inflating token counts. Free/early access availability is believed to have contributed to Grok’s 4.1 Fast surge.
Warning: Leaderboards are not everything.
Leaderboards can be helpful, but they are not a perfect proxy for the real developer value. Consider:
- Leaderboard Optimization vs. Generalization: Teams routinely optimize models for the metrics used by a benchmark. Companies have used contractor-led tuning or targeted data to improve their leaderboard scores. This practice can result in high benchmark scores, but does not guarantee better robustness. In the case of Grok, journalistic reporting has covered such efforts.
- Diversity in Evaluation is Essential: Different leaderboards are tested for different combinations (shortcode generation, bugfixes, longform reasoning, and tool use). One leaderboard entry does not necessarily mean you are the best at all coding tasks or code quality measures. Independent evaluations show mixed results across functions, such as reasoning, math, and coding.
- Token Accuracy: A high token count indicates usage intensity. However, higher token counts may be due to verbose outputs or repeated API calls during integration testing.
Grok Coding Leaderboard: Competition and the Market
Grok competes against major models (Google’s Gemini; OpenAI’s GPT-class models; Anthropic’s Claude), each of which excels in different areas, such as reasoning, hallucination control, or cost efficiency. There are tight margins in independent head-to-head tests and winners that depend on the task. For example, some tests rank Grok highly on specific coding metrics, while others prefer alternative models for reasoning and factual accuracy.
Grok coding leaderboard: Advice for developers and teams
- Select by task and not by headline: Different models are used for deep reasoning, production safety, or benchmark-specific benchmarks.
- Do not measure speed, but quality: Instead, track unit-test passes, static analysis metrics, and runtime accuracy, rather than relying solely on the appearance of a leaderboard.
- Beware leaderboard overfitting: You may see regressions when you use edge cases or opposing inputs.
- Identify the costs and latency of your environment: When integrated into production pipelines, free access spikes may mask paid costs.
Final Thoughts
The tweet about Grok being “parked at #1” is based on measurable signals, such as top leaderboard positions or massive token volumes on public routing platforms. These signals reflect real adoption (speed, context, and pricing). Grok is not a winner for every coding requirement. Savvy teams should view leaderboard positions, token counts, and other input as just one of many. They can also balance these with task-specific benchmarks and integration testing.
FAQs
1. Is Grok actually the best model for coding right now?
This depends on what you measure. The “Grok Code Fast” and other Grok builds often top public leaderboards for coding. But “best” is determined by code quality, hallucination rate, and task type. You can also create your own benchmarks.
2. Are high token numbers a sign of superiority?
No, they are merely a measure of usage. Usage may reflect popular demand, ease of integration, or promotional access.
3. Should I switch to Grok based on these reports?
Run a pilot to compare unit-test pass rates, latency, and cost with your current model. This will provide you with actionable insights for your workload.
4. Are leaderboard results reliable?
They’re informative, but imperfect. There are documented cases of teams optimizing their models for leaderboard metrics. Combine leaderboard data and independent testing.
5. Where can I see official Grok specs and pricing?
OpenRouter has model pages for Grok Code Fast 1 (and Grok 4.1 Fast), which list the context sizes, price frames, and providers. This is a good place to start when planning integration.
Also Read –
Grok Code Ranks #1 on BLACKBOXAI and Kilo Code Leaderboards
Grok Rankings Update: Full Breakdown of Grok 4.1 Fast and Grok Code Fast 1