
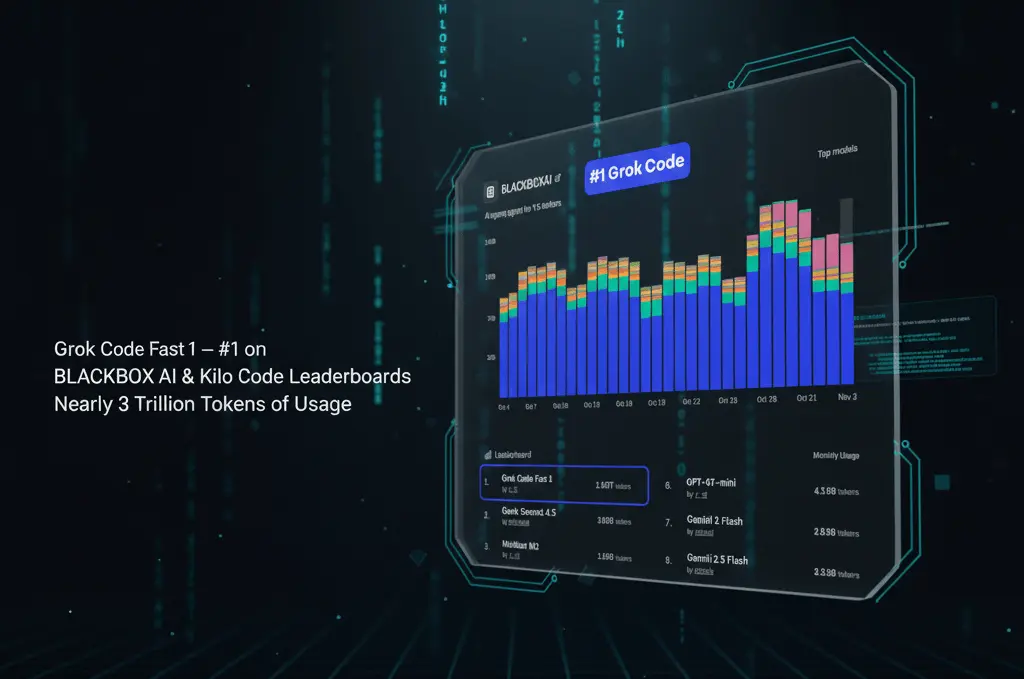
Recently, the team behind Grok Code Fast 1 (developed by xAI) announced that the model has secured the top spot on the BLACKBOX AI monthly leaderboard as well as Kilo Code’s monthly leaderboard. Kilo Code monthly leaderboard–setting a record at close to 3 trillion tokens of use. The announcement highlights the rapid acceptance of Grok Code Fast 1 in workflows for developers and signifies a shift in the market for large-language coding models.
What is Grok?
Grok is an advanced model of artificial intelligence created in collaboration with xAI, Elon Musk’s AI business. It is designed to compete with models such as ChatGPT as well as Claude. Grok specializes in real-time reasoning, code assistance, and multimodal comprehension. Grok Code Fast 1 ” Grok Code Fast 1” version is specially designed for developers, providing quicker token generation, bigger context windows, and improved understanding of code. It’s integrated into tools such as Blackbox AI and Kilo Code, which allow users to create, test, and automate their code faster.
How Grok Code Climbed to #1 in Real-World Usage?
Rank update- December Ranking
Unlike benchmark leaderboards that rely on academic or controlled testing environments, the Agentic Model Leaderboards (like those maintained by Kilo Code and BLACKBOX AI) reflect actual usage across developer communities. These boards track the volume of tokens processed by various models when used within tools such as a VS Code extension, making them a practical proxy for developer preference and engagement.
According to publicly shared usage data, Grok Code Fast 1 has maintained dominant usage figures, processing vast quantities of tokens, multiple times more than any other model on these charts. Some usage reports suggest it consistently processes over a trillion tokens weekly, holding a large share of the programming category on platforms like OpenRouter.
A specific report on the Kilo Agentic Model Leaderboard highlighted Grok Code’s dominance: it recorded four times the tokens of the nearest competitor among over 750,000 developers engaging via the VS Code extension. This suggests that real developers are choosing Grok Code not just for experiments but as an integral part of their coding workflows.
What Leaderboards Say About Us?
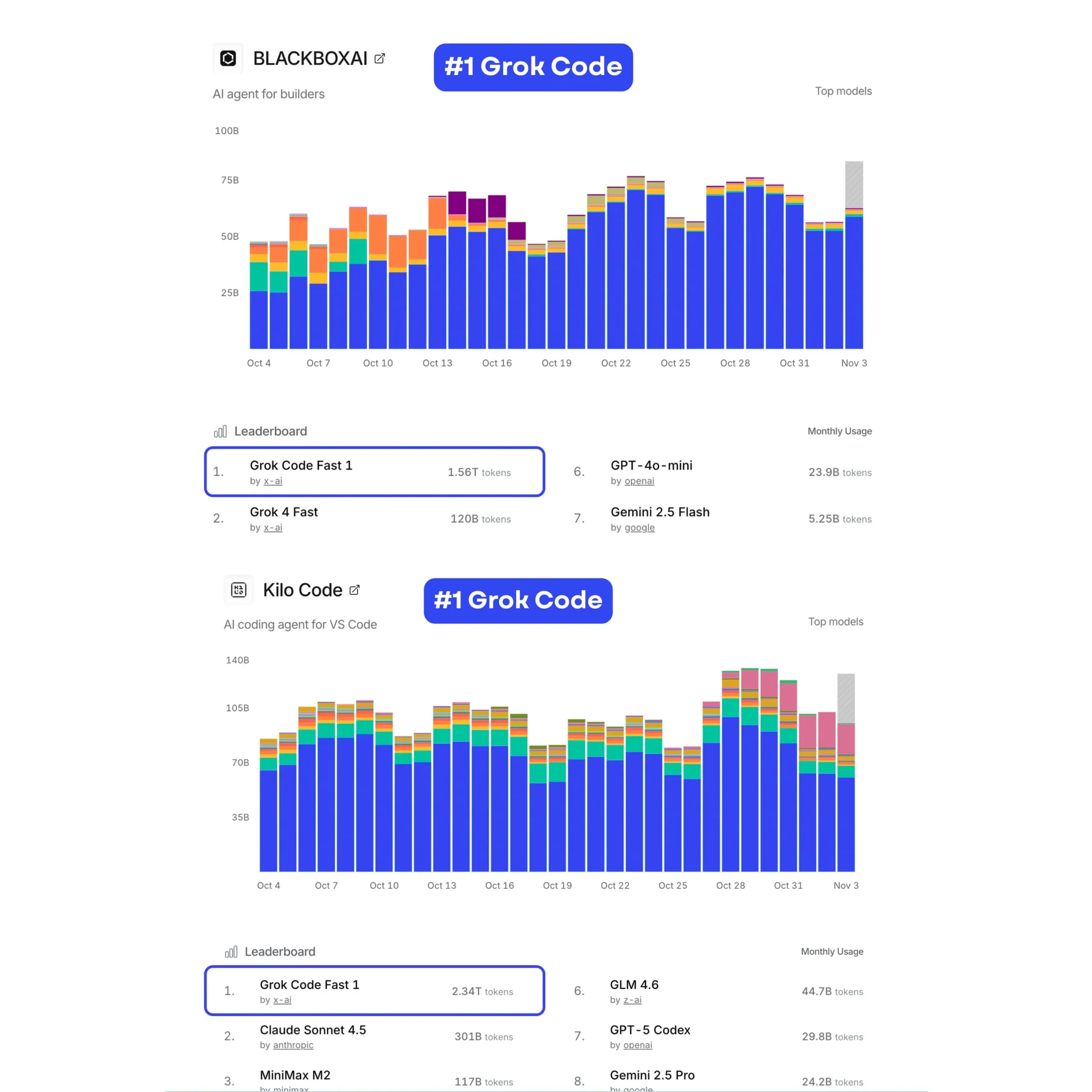
Leaderboards, such as those created in the form of BLACKBOX AI as well as Kilo Code, measure token usage and model acceptance across developers. Based on publicly available information:
- On OpenRouter (which tracks models used by various apps), the model “x-ai/grok-code-fast-1” has already logged among the highest token usage for the week/month.
- Kilo Code’s blog explained that just a few days after the launch, Grok Code Fast 1 achieved 76.5 billion tokens in three days thanks to this extension. Kilo Code extension.
- Another Kilo Code blog post described Grok’s rapid rise: “Within 96 hours … increased up to number one on the OpenRouter leaderboard and took home 66 percent of Kilo Code’s use share.”
- Twitter in the query (which has launched the article) reads: “Grok Code ranks first among the BLACKBOXAI as well as Kilo Code monthly leaderboards, almost hitting 3 trillion tokens of use .”
When taken together, the data suggest that Grok isn’t just doing well in benchmarks but is being utilized in real-world workflows for developers.
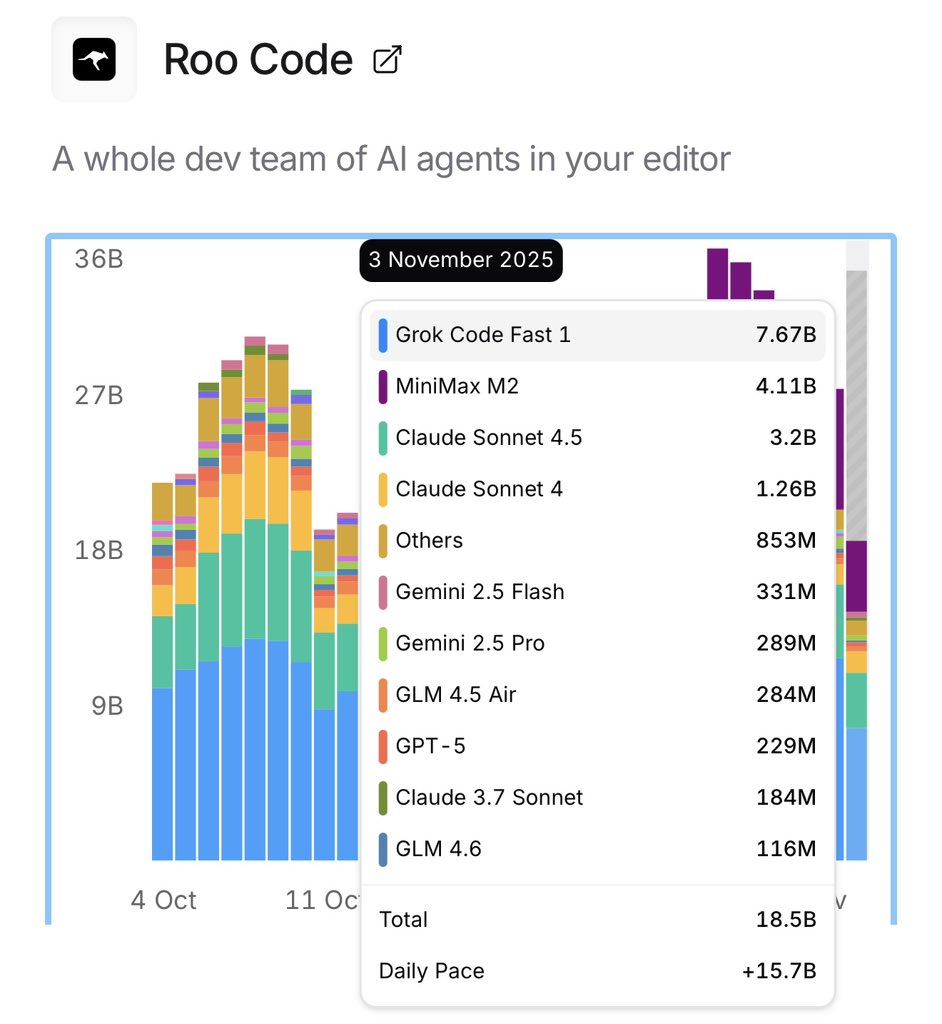
Roo code ranking for Grok Code
Why This is Important?
Its importance could be divided into several crucial areas:
Scale and adoption by developers
A total of 3 trillion tokens indicates a considerable amount of usage. If a token is equivalent to a single word or sub-word in a variety of models, it means that there are a lot of code interactions (prompt and response) across a wide range of users. This scale indicates it’s possible that Grok Code Fast 1 isn’t only being evaluated — it’s embedded into workflows. For developers, a high use of tokens can lead to savings in costs, speed improvement, and a higher level of productivity.
Competitive positioning
In topping not just one, but two of the most popular month-long leaderboards (BLACKBOX AI and Kilo Code), Grok sends a clear signal to rivals like Claude Sonnet 4.5 (from Anthropic), Gemini 2.5 Flash (from Google), and others. According to the OpenRouter rankings, Grok Code Fast 1 was at the top of its particular category (“programming”) with a token share.
Capabilities of the model and trustworthiness
The achievement confirms the fact that Grok Code Fast 1 isn’t an exclusive or “toy” model, but is actually being utilized in commercial settings. Test results show a high level of performance, for instance, an evaluation test of coding showed the Grok Code Fast 1 scored a “respectable 7.64 average score” for a wide range of programming tasks. The information on token usage in conjunction with performance evaluations adds credibility.
Cost vs performance trade-off
One of Grok Code’s benefits is its ability to be optimized for high throughput, including large context windows, quicker token generation, and being targeted towards the efficiency of developers. According to one blog: “context window: 262k tokens and around 190 tokens per second, speed: 70.8% on SWE-Bench with 90% hit rates on caches.” Due to the vast quantity of usage, numerous teams could be looking at throughput, and it costs more than absolute benchmark scores.
What’s Behind the Surge?
A variety of factors are believed to contribute to the rapid growth of Grok Code Fast 1:
- Integration with Tools for Developers – The model is available via Kilo Code (a VS Code extension) and through the BLACKBOX AI workflows. In integrating the model in tools that developers already use, friction decreased, and usage increased.
- Aggressive Pricing/Free-Promotion – For example, Kilo Code’s blog noted that during the early launch period, the model was available with free access/no rate limits in the extension, which naturally accelerated adoption.
- Context Window and Speed Benefits – The model was developed for speedy workflows in coding; large context windows enable complete code bases as well as multiple file types to be processed. Speed allows developers to build faster.
- Positioning and Timing – The market for AI programming assistants is booming. With developers looking to increase productivity, a system that can provide the highest throughput and lower cost can be very appealing.
- A compelling Launch Story and Strong Marketing – The launch of Grok Code Fast 1 was followed by blog updates, developer reports, and announcements about public ranking. This creates word-of-mouth momentum.
Grok Code Fast 1: Potential risks and considerations
Although the achievement is significant, it’s not without a few stipulations or issues users and teams need to consider:
- Leaderboard Usage is of Perfect Quality – The metrics of token usage and leaderboard rankings reflect scale, but they don’t necessarily ensure absolute accuracy or suitability for every use case. For instance, when it was evaluated, Grok Code Fast 1 performed “surprisingly poorly” in some tasks (Tailwind CSS V3 z-index bug), getting just 1/10 marks in one instance.
- Model specialization vs generality – It appears to be specifically designed for the workflow of developers (autocomplete programming tasks and terminal commands) instead of all-purpose reasoning for general-purpose languages. Teams must determine if their strengths are in line with their own needs.
- Dependency risk – High adoption means dependency. Organizations that use Grok extensively should consider the impact of vendor lock-ins, model updates, as well as changes to versions, and the cost implications as use increases.
- Benchmark gaming – A few industry commentators warn that the dominance of leaderboards sometimes results from optimization of specific jobs, not broad-based utility. (See e.g., discussions about different benchmarks and models. )
- Controlling costs – The high volume of tokens used can translate into material costs. While the expense for inputs is small (e.g., ~$0.20 for every million tokens input) in the initial reports, the output cost and caching strategies should be analyzed.
What does this mean for the Team and Developers?
If you’re an engineer or a team that is considering a coding-based AI assistant, there are a few lessons that can be learned from the milestone.
- Analyse the Throughput and Costs – Cost and throughput: If you are involved in a lot of iterations, have a huge codebase, or are in interactive loops, an approach such as Grok Code Fast 1 that is optimised for throughput can yield a high return on investment.
- Examine the Workflow to See if it is a Good fit – Since speed and token count are two significant benefits, try the model out in the actual editor/IDE configuration (VS Code + Kilo Code or BLACKBOX integration) to test how it will work with your workflow.
- Blend Models When They are Needed – If you require deep reasoning architecture suggestions, extremely complex model analysis (e.g., Tailwind bug scenario), you might want to consider combining models that focus on these strengths.
- Plans for Scaling – with the adoption comes cost and management. Check the use of tokens in addition to caching strategies, quick engineering, and maintenance of integrations and prompts.
- Keep up-to-date on Changes – Models are constantly evolving. Being top-ranked today does not guarantee that you will be a leader in the future. Examine models, model updates, changes to versions, as well as community feedback.
Final Thoughts
This announcement that Grok Code Fast 1 has been ranked #1 in both BLACKBOX AI as well as the Kilo Code monthly leaderboards–while approaching an astounding 3 trillion token usage — marks an essential milestone in the field of coding-AI. This indicates that the system is being used on a large scale, integrated into developers’ workflows, and used as a tool to improve productivity instead of just an interest in benchmarks.
For engineering and development teams, it means that there’s an efficient, high-throughput solution to generate code and workflows for iteration. However, it’s a reminder to take note of the following factors: size and speed are essential, as are precision, accuracy, domain fit, cost, and integration of tools.
As the AI models for coding continue to change and grow, the success of Grok Code gives another perspective on the “arms race” of models that are designed for developers. If you’re thinking of incorporating an AI coder into your workflow, this achievement suggests that Grok Code Fast 1 is worthy of a benchmark.
If you’d like to know, I’ll be happy to examine Grok Code Fast 1 side-by-side against other coding models that are leading (e.g., Claude Sonnet Gemini 2.5, Qwen Coder) with respect to cost and speed, as well as accuracy and the ecosystem and fit.
FAQ
1. What is the exact meaning of “3 trillion coins” translate to in this instance?
The announcement mentions “nearly three trillion tokens of use” on the top leaderboards of Grok Code Fast 1. This is the total number of tokens that are processed (both input and output) within the workflows of code developers through the platforms that are tracked (BLACKBOX AI and Kilo Code). A token is typically the size of a text block (which can be as tiny as the size of a sub-word). This scale indicates a pervasive use, probably for many users and numerous sessions.
2. How trustworthy are these leaderboards?
Leaderboards like those provided by Kilo Code and OpenRouter provide transparency in the metrics of the use of their services and also share model shares. For instance, Kilo Code shows monthly top models on their dashboard. However, a ranking of usage doesn’t necessarily mean the highest quality or a good fit to your specific requirements. Additionally, the metrics of leaderboards can be affected by promotions or free credits, early access strategies, and integration with popular platforms.
3. Does being ranked #1 suggest that Grok Code Fast 1 is the most efficient coding model?
It’s not necessarily “best” in all aspects; however, it is undoubtedly the most widely used (or among the top widely used) in its field on a larger scale. The evaluation results provide excellent performance (average rating of 7.64) but also show weak points (e.g., Tailwind CSS task). For many tasks, it’s fantastic, but teams must nevertheless verify the quality and fit for their specific domain.
4. What is BLACKBOX AI, and Kilo Code, exactly?
- BLACKBOX AI can be described as an AI agent platform and development environment that allows developers to integrate large language models for programming as well as AI agents to work in workflows.
- Kilo Code is a VS Code extension and developer tool that allows AI-coding agents. It creates the “Kilo agentic model leaderboard” listing, which models are most frequently used by its 500k+ developers.
- The top spot in both ways, Grok is not only active in multiple ecosystems, but also is leading them.
5. What’s changed with Grok Code Fast 1 when compared to the previous models of the xAI?
The most critical distinctors are:
- A large context window (reported ~262 k tokens), allowing codebases, multi-file contexts, etc.
- High throughput of tokens (speed around 190 tokens per second) to speed up the number of iteration cycles.
- Pricing is designed to encourage the use of high volumes in workflows for developers.
- Promoting early access to HTML0 through Kilo Code and integration into developer tools, facilitating rapid adoption.
6. Should I move right away to the use of Grok Code Fast 1 for all my projects?
It is advisable to review before committing to a full-time adoption. Consider:
- Do you have a workflow that involves large-scale, frequent code iterations or processes for IDE or terminals? This model might be an excellent fit for your workflow.
- Do you require an in-depth understanding of architecture, domain-specific knowledge, and extreme precision in specific frameworks (e.g., special CSS frameworks or domain logic research) in which other models could be better than yours? It is possible to test a variety of models and evaluate them.
- Monitor costs and token usage caching, cost, and engineering costs as your usage increases.
- Pay attention to model revisioning, vendor support, and the level of reliability.