

In November 2025, xAI revealed a new series of accomplishments with two top AI models,Grok 4.1 Fast and Grok Code Fast 1. Grok Rankings Update Nov showcases these models atop a variety of leaderboards based on user benchmarks, as a sign of xAI’s ever-growing goal to go beyond a single chatbot for all purposes towards a diverse AI toolkit optimised for specific tasks.
Grok 4.1 Fast is marketed as xAI’s agentic model, focused on tool-calling, long-context reasoning, and multi-step workflows. Additionally, Grok Code Fast 1 remains the leader in large-scale coding workflows, making xAI a prominent player in software development.
In combination, the release is a shift in strategy to a more flexible approach. Instead of a one-size-fits-all approach, xAI is investing in custom-built AI engines tailored to specific real-world applications.
In this article, you will get to know about the Grok Rankings Update, the performance of Grok 4.1 Fast and Grok Code Fast 1, and how these models achieved top positions across key AI benchmarks.
What is Grok 4.1 Fast, and Why It Matters?
Grok 4.1 Fast was released publicly on the 19th of November, 2025.
Essential technical capabilities
- Massive capacity for Context: The model supports a 2-million-token input window, allowing it to analyse and ingest large documents, lengthy conversation histories, and multi-file contexts.
- Tool-Calling through the Agent Tools API: this API enables Grok 4.1 Speed to connect to external tools, including web search and live data, remote execution of code files, and more. It also allows it to operate as an independent agent.
- Two Runtime Modes- Reasoning and Non-Reasoning: Developers can select between the reasoning mode (for complex, multi-step reasoning and organised outputs) and the non-reasoning mode (fast, low-latency).
- Cost-Effective and Production-Ready: xAI describes Grok 4.1 Rapid as a model optimised for speed, tool integration, and token efficiency. This makes it ideal for workflows that require enterprise-scale resources, not just for research demonstrations.
Also Read - Grok Code Ranks #1 on BLACKBOXAI and Kilo Code LeaderboardsWhat are the Real-World implications of this?
In light of these design choices, Grok 4.1 Fast can offer new possibilities for AI-driven apps:
- Large-document processing and analysis, for example, writing and summarising lengthy legal documents and regulatory documents, as well as research papers (many hundreds of paragraphs or pages).
- AI agents to automate workflows, bots that determine, read, and access APIs, collect data, and create well-structured outputs on their own (for customer assistance, information retrieval, research, compliance, etc).
- Lang-form thinking and plan multi-step plan, chained operations, rich context dialogues, or even project-level AI assistants that retain memory during prolonged interactions.
Since it is a tool, it has long-term memory and structured output. Grok 4.1 Fast isn’t simply a more intelligent chatbot, it’s also a foundational component for AI agents that can be used in production.
Where Grok 4.1 Fast & Grok Code Fast 1 Stand Out: Benchmarks and Rankings?
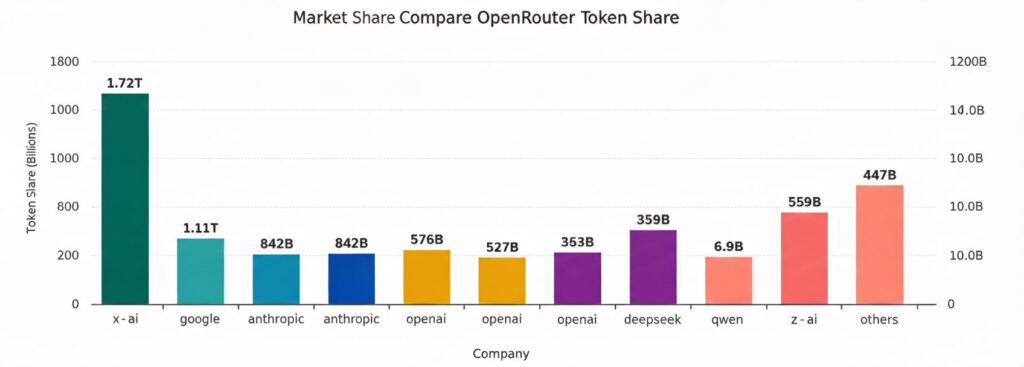
As per the November update, Grok 4.1 Fast and Grok Code Fast 1 have achieved top positions across a range of usage and performance metrics. Although the summary of the update does not always align with independent third-party audit reports, the claims are supported by xAI’s documentation and external validation.
What are the claims of the update?
- To Grok 4.1 Fast: the top spot in the most difficult agentic tool-use benchmarks (e.g., theT2-bench Telecom, which is said to mimic mission-critical real-world workflows). It is also believed to be the best in function-calling accuracy (via the Berkeley Function Calling benchmark) and to lead in usage-based performance for programming-related work (by token shares).
- For Grok Code Fast 1: The dominance in coding-focused use, the most popular token across all kinds of models, capturing the most traffic for English-speaking LLMs, and topping various leaderboards of code-related apps.
In total, these ratings place Grok 4.1 Fast as the most powerful agentic AI engine and Grok Code Fast 1 as the most recommended LLM for high-volume coding tasks.
Uninvolved assessment and early Reception
Tech analysts note that they believe the Grok 4.1 Fast’s 2M token context and tool-calling built-in feature is among the biggest models based on agent release dates in 2025. Many early testers and developers consider it more than another LLM update. Still, a sign that agent-based AI, that is, the kind able to speed up or automate lengthy workflows, is becoming a reality.
However, some caution remains. Because a large portion of benchmark results comes from xAI or related documentation, third-party audits by independent auditors are still somewhat limited. Like every new frontier release, widespread adoption will be contingent on thorough testing, real-world deployments and a mature set of safeguards to ensure safety, reliability, and conformity.
Grok Code Fast 1: The Coding Powerhouse
Although Grok 4.1 Fast has been a hit for its tool-calling capabilities and long-context reasoning, Grok Code Fast 1 is still xAI’s king of coding workflows. The release was earlier in 2025. Grok Code Fast 1 was developed to provide quick, efficient, cost-effective coding assistance, perfect for developers and automated code tools and pipelines for high-volume generation.
Due to its rigour and efficiency, it is said to lead in popularity and usage of tokens across a variety of coding platform leaderboards. This implies that many members of the developer community depend on it for everyday programming tasks, large-scale batch workflows, and automated code generation.
In essence, Grok Code Fast 1 and Grok 4.1 Fast represent two different engines in xAI’s ecosystem, one for coding and the other for long-context reasoning and agentic workflows.
What does this signal for the Future of AI?
Updates for November and their meaning are crucial not only for xAI but also for the wider AI landscape. Several broader trends emerge:
- Specialisation over “One-Model-Fits-All”: Rather than pushing a single generalist model, xAI is embracing a multi-engine strategy. This could mark the beginning of a shift toward “biggest model wins,” with specific models designed for particular jobs.
- Agentic AI getting Ready for Production: With APIs for tool-calling with long context windows as well as structured output AI software that can think, retrieve real-time data, make decisions, and deliver actionable outcomes -not just text- are now becoming practical at a greater scale.
- Enterprise Developer-Friendly use: By providing models designed for code and document processing workflow automation, tool integration, xAI is likely to appeal to developers, businesses, as well as enterprises, not only people who use chat services for personal use.
- Competition for Benchmarks is Heating up: As tasks that require agentics, longer-context analysis, directed outputs and tool-calling are becoming more important, the introduction of innovative benchmarks (e.g. tools-use benchmarks, agentic index, tasks that require document length) will likely fuel the competition between AI providers, more so than raw parameters or traditional “creativity” benchmarks.
In the simplest terms, xAI’s new version suggests 2025 could be the year a major shift occurs, shifting the focus from chatbot AI to agentic AI platforms.
What to Watch Out For: Cautions & Open Questions?
Despite all the excitement, there are legitimate issues and unanswered questions:
- Independent Verification is not as Robust: The majority of benchmarks and performance claims originate from xAI or other measurement platforms. More extensive, community-based audits as well as real-world stress tests are required.
- Safety, Compliance, and Integration Risk: The ability of AI models to access external APIs, run programs, search the internet or real-time data, or alter documents can raise security, privacy, and reliability concerns. Companies that implement AI systems using these methods will require robust security guardrails, sandboxing, and supervision.
- Specification Trade-offs: Models designed for use with tools and programming could not perform as well in other fields like creative writing, open-ended dialogue, complex reasoning, or different, more subjective tasks, which could still benefit from more general or differently tuned models.
- Cost and Resource Aspects: Handling 2M token contexts and large-scale code generation incur computational costs; however, while xAI makes the models appear cost-effective, the actual deployment costs will depend heavily on use patterns, tools, and integrations.
For Whom Grok 4.1 Fast & Grok Code Fast 1 Make Most Sense?
These specialised models are likely most valuable for:
- Businesses that require Automation, e.g., bots for customer support, automated document analysis and ingestion, compliance screening, report generation, and many other workflows in which tool-calling and structured output are essential.
- Developers and Teams with a lot of Code to assist with massive code, automatic refactoring, code scaffolding, and massive-scale projects that can benefit from speedy, efficient, and reliable Coding aids.
- Data-intensive or Research-Related tasks that require long-form documentation analysis and summarisation of multiple documents, extraction of data from extensive collections, or research assistants who need the ability to keep Context across vast amounts of data.
- AI product Developers who build Applications, agents, platforms, or applications that integrate AI with tools (e.g. search, summarisation, execution and reporting).
For general AI users, such as informal chat, creativity, writing, and brainstorming, alternative models might be better suited.
Final Thoughts
This Grok Rankings Update represents more than just a brag page and signals a significant change for xAI and the broader AI industry. By launching Grok 4.1 Fast along with Grok Code Fast 1, xAI has signalled its belief that the future of AI lies in highly specialised engines specifically engineered for tasks, such as tool-calling agents, big-context processors, and coding assistants.
Suppose the benchmarks are held to greater scrutiny. In that case, we could be witnessing a shift from chatbots as novelty items to AI agents as infrastructure, which enterprises, developers, and data-intensive workflows will rely on. For software developers, analysing large documents or automating multi-step processes could mark the start of a new phase in AI adoption.
However, as with all the latest developments in AI, caution is recommended. Independent audits, security practices, and cautious deployment will be essential. The word is accurate. The work has only started.
FAQs
1. What does “Agentic Model” mean in this Context?
The term “Agentic model” refers to a model that is not just for the generation of text but to mimic the behaviour of agents: making decisions about which tools to call (e.g. code execution, web search), managing workflows with multiple steps, as well as handling context windows that are long and autonomously orchestrating tasks. Grok 4.1 Fast and its API for tool-calling, with 2M tokens for context windows and RL training to use tools, fits this particular profile.
2. How does the size of the Context Window matter?
The context window determines the amount of text (or other information) the model can retain in a single instance. A 2 million-token window indicates that Grok 4.1 Fast can ingest and analyse large document batches, multiple documents, or lengthy conversations, which is crucial for document analysis, long-form thinking, and complex workflows.
3. Are these Benchmarks Independently Confirmed?
Some results, such as the T2 Benchmark (t2-bench) and the telecoms benchmark, have been independently confirmed by analysts or third-party reviewers. However, many assertions are made by xAI or other affiliated companies. As with any newly released AI, a more thorough independent analysis is essential before relying on broad claims.
4. Does this mean Grok is now “better” than competitors like GPT-5 or Gemini 3 Pro?
It’s based on the job. For tasks that require agents’ tools, tool invocation, lengthy context reasoning, and customer support workflows, Grok 4.1 Fast has an advantage. For high-volume coding workflows, Grok Code Fast 1 is widely regarded as the best option. But for other types of tasks (creative typing, nuanced dialogue, and multimodal reasoning), Different models might still excel. There isn’t a universal standard at the moment, just the best for this specific use case.
5. What are some possible drawbacks, or trade-offs?
Agentic models raise extra security, safety and complexity concerns. Integration of tools increases attack surfaces. Long-context reasoning can introduce new mistakes, and specialised models could fail in general or on creative tasks. Furthermore, reliance on external APIs and tools is essential for robust engineering and adequate protection.
Also Read –
Grok Rankings Update: Token Usage, Leaderboards & Market Share (2025)